UTCTF
UTCTF是由德克萨斯大学奥斯汀分校的信息与系统安全协会运营的,面向全世界所有人。此次正好是一个练手机会,最终排名第20,其中主要做了一些web和流量分析的题目,这里简单写下wp。
HTML2PDF
解题思路
题目是一个把html转为PDF的功能。
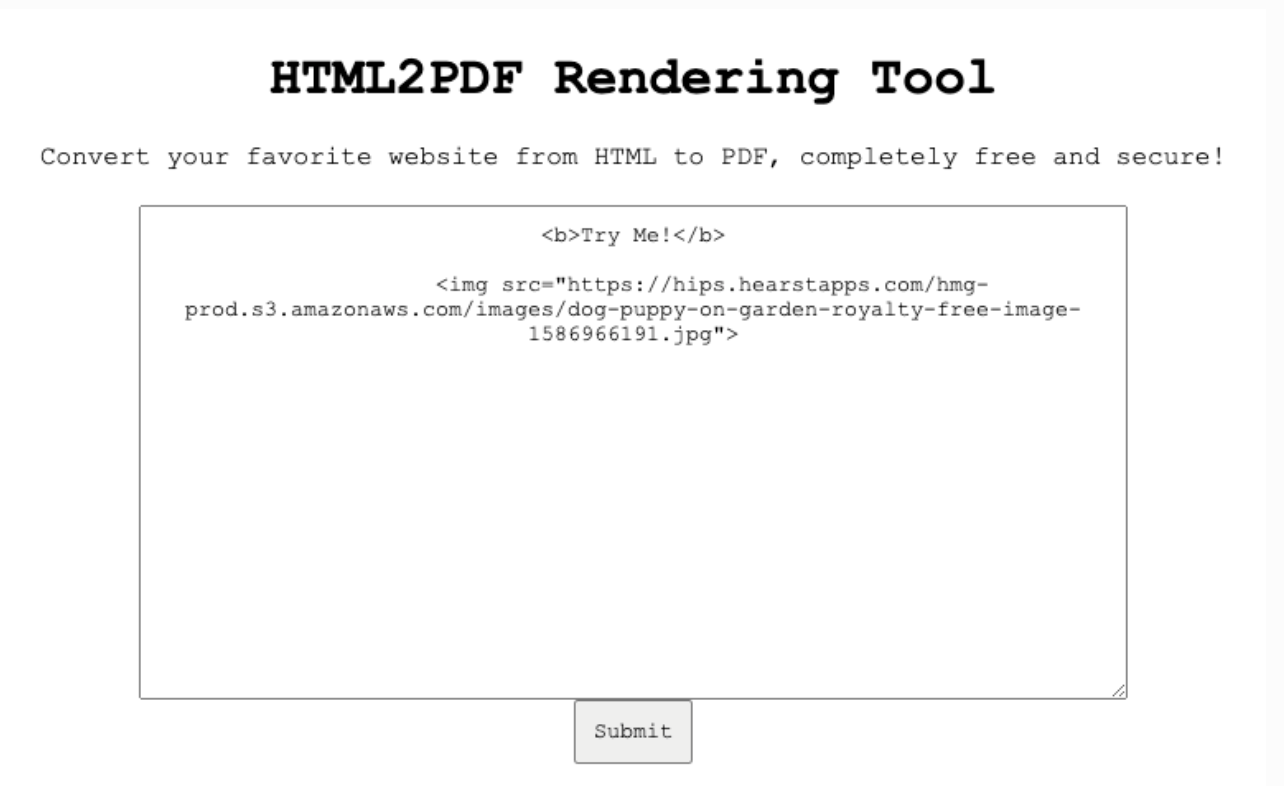
这里由于题目关闭没有渲染后的PDF截图了,大致就是一个图片渲染进去了。我们通过下载这个PDF文件,并查看文件内容可以看到我们的图片确实是被解析了。说明我们的代码是被执行了的,所以此处存在xss,现在我们就是需要利用xss来读取文件。
其实这里面还有一个细节就是大部分第三方组件生成的PDF都在头部信息有标明,这就涉及到信息搜集的敏感度了。一般在PDF文件头信息或者是burp的响应中能看到关键组件信息,有时候他也存在于响应的UA中,此题目通过下载的PDF头查看到用的是wkhtmltopdf组件,此组件网上也有现成的漏洞资料。
https://blog.noob.ninja/local-file-read-via-xss-in-dynamically-generated-pdf/
常理说我们不应该可以直接iframe进行文件读取,比如下面这样通常会有问题
1 | <iframe src="file:///xxxxx/xxxxx/*.py"> |
我们先来看看常见情况下iframe标签读取会遇到什么问题?
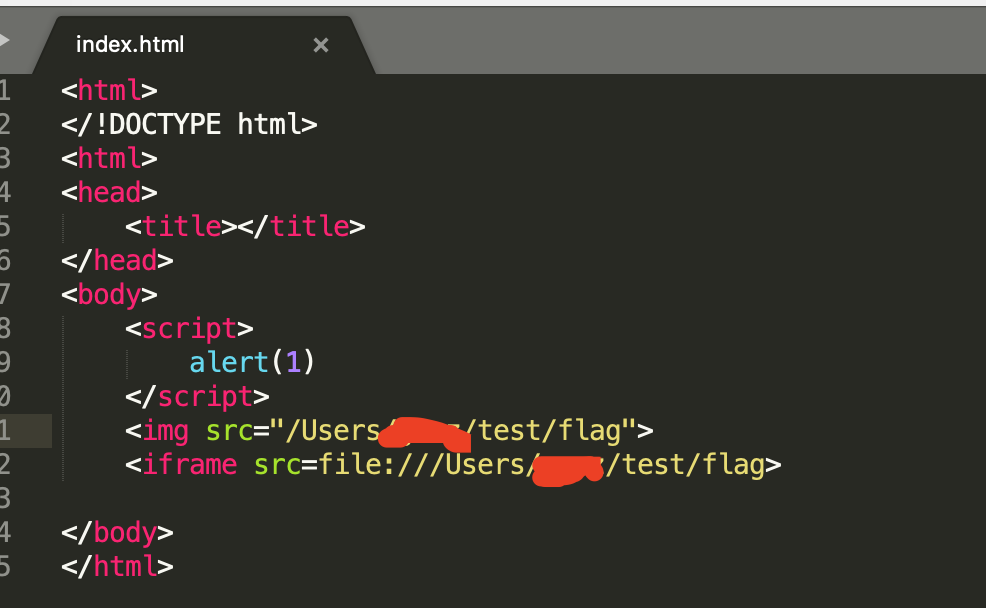

可以看到提示跨域http协议不能file协议读本地文件,因为file协议和http协议不同源,所以我们在一些xss中无法使用上面的代码进行文件获取。
但是因为wkhtmltopdf在转换pdf的时候使用的是file:///var/www/xxxxx/test.html 这种读取的本地html文件,所以我们此处用iframe的src file协议即可同源读取。
但是如果我们直接读取 file:///etc/passwd 会发现读不到,这是因为从Gecko 1.9开始,file协议中的文件使用了更细致的同源策略,只有当源文件的父目录是目标文件的祖先目录时,文件才能读取另一个文件。所以我们仍需要想办法跨域。
这里用的是XHR跨域读取本地文件
1 | <script> |
拿到shadow,直接看密码,登录即可得flag

拓展
那么如果遇到跨域问题我们如何进行跨域的读取呢?
这里我们可以通过两种方式来实现
CORS跨域资源共享
CORS跨域资源共享是目前的主流方案,基本所有浏览器都支持,当然IE需要版本新一点。CORS跨域资源共享本质是一种协约。
原理就是浏览器通过XMLHttpRequest发送跨域请求,并自动添加一些附加header信息,同时服务端约定了Access-Control-Allow-Origin(允许的跨域请求域名)和Access-Control-Allow-Methods(允许的跨域请求方式)响应头,如果符合标准则返回资源内容,否则一般是403。
当然一些复杂请求比如跨域的PUT和DELETE会稍微复杂一点,会先OPTION预请求下服务端同样验证通过后再进行下一步的跨域请求,此处的实现细节和简单的GET和POST请求可能略有不同,此处不在展开,以免占太大篇幅,以后有机会再详细讲讲。
那么基于此我们就知道如何进行跨域请求了:XMLHttpRequest
payload1:
1 | <script> |
上面可以跨域 但是真正能不能请求成功需要看服务端的Access-Control-Allow-Origin(允许的跨域请求域名)和Access-Control-Allow-Methods(允许的跨域请求方式)两个字段的规则
由于此题目的Origin是file:// 所以此处符合同源策略可直接读取。
JSONP
jsonp跨域就是把想要跨域的内容直接当作js请求返回,众所周知
1 | <script src=http://xxxx.com/dsadsa.js>标签是可以跨域的 |
这个一般不好利用来读取本地文件,但是他也存在一些其他的安全问题,这个以后再说。
Websockets
打开题目就是一个网站展示页
其中login url有一个登录端口
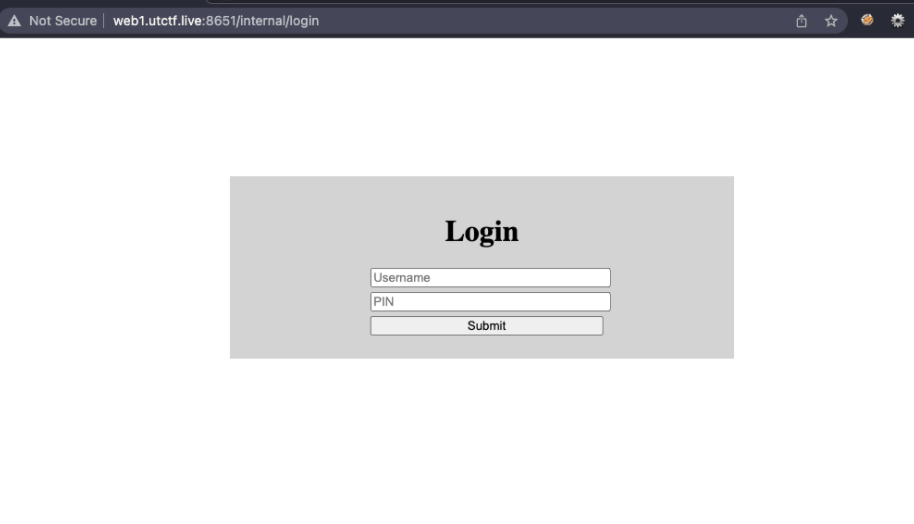
输入错误的用户名会提示用户名不存在,如果是正确的则是pin不正确,所以基于此可以确定用户名admin,然后F12查看源码
1 | <div class="topbox"> |
可以知晓是三位数字爆破,但是这里考察的是websoket爆破,因为通信是websocket协议
我们直接写一个python脚本
1 | #!/usr/bin/env python3 |
登录即可获取flag
ReReCaptcha
这道题目的考点其实很明确,就是要连续正确识别1000个验证码。
首先测试可以得知每个cookie都对应了一个验证码,且记录了正确的次数,这可以保证我们即使识别错误依然可以回退到上一个验证码的cookie,不必从头开始。至于验证码识别我常用的是muggle模块,但是验证码过于复杂,无法识别,此处需要过滤噪音。我一个同事发现此验证码的背景图片几乎一致,如果我们把背景图片抠出来然后再xor就能拿到纯验证码的图片,然后再muggle识别就ok了。
最后我们抠出如图

尽管xor后的图片仍然可能比较模糊 但是正确率已经足够
最终我们获得了flag
网上别的wp用的python ocr是 pytesseract 这个大家可以合理参考。